

AI o non AI: questo è il dilemma
DISCLAIMER: Le opinioni contenute in questo articolo sono interamente frutto delle mie conoscenze, studi ed esperienze vissute in prima persona.
Ai tempi dell'Università ho avuto più volte a che fare con lo strato teorico su cui poggia tutta la teoria delle reti neurali e, più in chiave moderna, degli LLM.
L'idea di mimare il comportamento delle reti neurali biologiche al fine di sviluppare un modello probabilistico che potesse affrontare alcuni problemi che gli algoritmi classici deterministici non potevano spingersi ad affrontare (non in maniera semplice, almeno) - bene questa idea non è certamente nuova e precede di gran lunga la diffusione dei cosiddetti Large Language Model. Le applicazioni classiche di questi modelli erano essenzialmente da ricercarsi in ambiti come riconoscimento vocale, immagini (per esempio testi scritti a mano), voice recognition, pattern recognition, ecc... Tutta questa roba la si usava già a livello consumer negli anni '90 o primi anni 2000 e personalmente ne ho memoria.
Reti neurali in a nutshell
L'idea di base di una rete neurale (informatica) non è così complessa da capire: nella sua forma più semplice, una rete è composta da un blocco iniziale di "elementi computazionali" chiamati neuroni che ricevono l'input esterno e, attraverso una funzione di attivazione, producono un output. Questo segnale si propaga verso uno o più layer intermedi attraverso delle linee pesate in cui ciascun neurone di input è virtualmente connesso ai neuroni dello strato successivo (potenzialmente a tutti i neuroni, nel caso di reti fully connected). Ciò che varia è il peso di queste linee e quindi l'influenza che il valore di ciascun neurone esercita sui neuroni dello strato successivo. In formule, il calcolo di un generico neurone si può esprimere formalmente così:
yj = φ( Σi=1n wij · xi + bj )
dove:
- xi è l’i-esimo input del neurone
- wij è il peso che collega l’input i al neurone j
- Σ wij xi è la somma pesata degli input
- bj è il bias del neurone j
- φ(·) è la funzione di attivazione per esempio ReLu o la funzione sigmoide
- yj è l’output finale del neurone
Alla fine di questa sequenza di layer intermedi, vi è lo strato finale composto da un blocco di neuroni il cui valore calcolato non viene propagato ulteriormente ma rappresenta l'output finale fornito dalla rete.
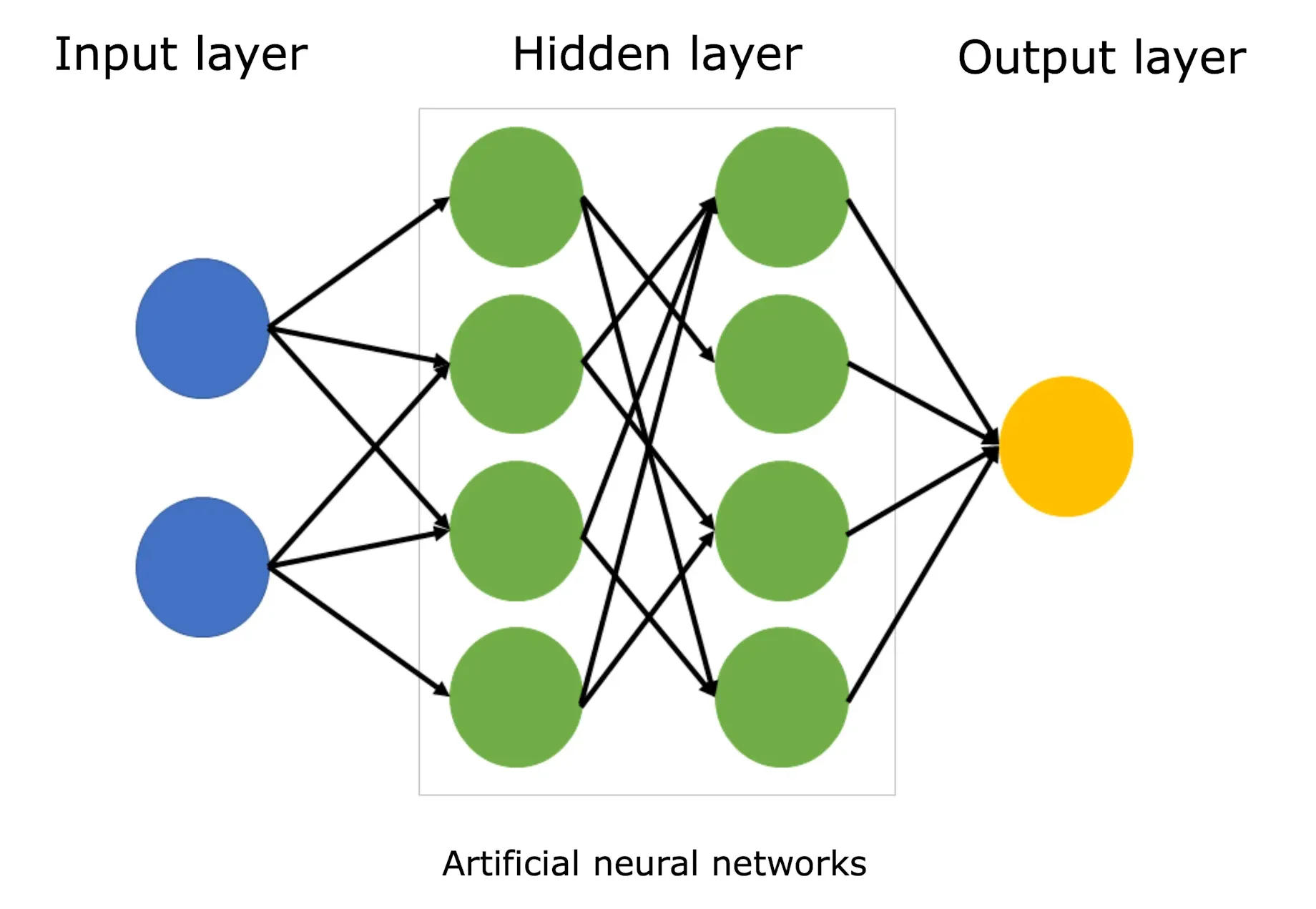
Chiaramente il modello fin qui descritto non è sufficiente a spiegare tutto il funzionamento della rete: esistono infatti delle procedure per modificare i pesi di ciascuna linea in base al compito che la rete deve soddisfare o in base al tipo input che la rete deve gestire. Esistono inoltre altri parametri come i bias che consentono di shiftare in alto o in basso (come delle costanti) la soglia di attivazione di un determinato neurone, aumentando o diminuendo la probabilità che quel neurone si attivi in determinate situazioni.
E' bene far notare che la funzione di attivazione summenzionata è di fondamentale importanza per le performance di una rete neurale: senza di essa, infatti, la rete neurale potrebbe immagazzinare soltanto delle relazioni lineari tra l'input e l'output! L'introduzione di una non-linearità (la funzione di attivazione, appunto) permette alla rete di imparare dinamiche complesse nel dominio dei dati che la rete stessa dovrà gestire. L'espressività della rete è dunque fortemente influenzata dalla presenza della funzione di attivazione, senza la quale eseguirebbe una mera combinazione lineare dei valori di input con dei pesi. Niente di più, niente di meno.
Generalmente le procedure atte a determinare i valori dei parametri della rete sono le procedure di training, cioè il procedimento attraverso cui una rete viene addestrata a imparare la conoscenza necessaria per il dominio in cui la si sta impiegando. In effetti tutta la conoscenza che viene fornita in fase di training viene immagazzinata sotto forma dei pesi e dei parametri di cui abbiamo parlato prima. Intuitivamente, maggiore è il numero di parametri, maggiore è la capacità della rete di immagazzinare informazione e pattern e, quindi, "riusarla" quando verranno presentati i veri input. Non si tratta di una proporzione lineare e sicuramente dovremmo almeno menzionare i problemi di overfitting, che si verificano quando la rete impara "troppo bene" i dati di training e non è molto efficace con altri input, vanificando gli intenti predittivi per cui una rete neurale è generalmente progettata. Un possibile modo per aumentare il numero di parametri è aumentare la quantità di hidden layers, cioè il numero di strati di neuroni che l'input deve attraversare per formare l'output finale, oppure il numero di neuroni per layer.
In questa mia breve sintesi ho saltato un mucchio di concetti... Ad esempio: qual è il meccanismo (o funzione) attraverso cui il neurone si attiva? Come vengono usati i dati di training per aggiustare i parametri della rete? Per approfondire questi e altri interessanti temi teorici vi consiglio una lettura free che abbina l'approccio matematico a qualche dritta più pratica per esercitarsi e implementare qualche rete neurale sulla propria macchina:
Ce n'è per tutti i gusti: algebra lineare, elementi di analisi, matrici jacobiane e algoritmi di back-propagation per il tuning dei parametri.
Dalle reti neurali alle AI moderne
Tornando ai giorni nostri, quello che davvero ha cambiato le regole del gioco rispetto ai tempi in cui bazzicavo all'Università, è l'aumentata potenza di calcolo adesso a disposizione. Il fatto di poter contare su acceleratori grafici molto potenti (particolarmente adatti al calcolo parallelo) rende possibile l'impiego di reti con miliardi di parametri, capaci quindi di immagazzinare un quantitativo di informazione senza precedenti.
Non solo, nel 2017 il reparto R&D di Google ha progettato una nuova architettura molto sofisticata di rete neurale chiamata Transformer. Questa architettura viene descritta per la prima volta nel paper "Attention is all you need" (link) e propone un'alternativa molto più performante delle tradizionali reti neurali (RNN e CNN, reti neurali ricorrenti o convoluzionali) in una grande varietà di task, come ad esempio la traduzione di frasi da una lingua all'altra oppure la generazione di testi, riassunti, sommari, ecc. Il Transformer è basato principalmente su uno stack di blocchi encoder/decoder posti in cascata e, soprattutto, sul concetto di attenzione. Questo concetto era già noto nella letteratura ma fu la prima volta che venne usato all'interno di una rete neurale in sostituzione ad altri meccanismi (RNN e CNN).
L'attenzione serve ad arricchire ciascun token in input (i token sono le parole, o parti di esse) col contesto della frase che lo circonda. Questo equivale a proiettare ciascuna parola in uno spazio vettoriale molto grande dove "vivono tutte le parole" possibili. Attraverso il contesto e il meccanismo di attention, questi vettori vengono spostati/ruotati/compressi/espansi per avvicinarli al loro significato semantico più corretto. Ad esempio, la parola "apple" usata in un testo che parla di abitudini alimentari dovrebbe essere avvicinata allo spazio di vettori relativi alla frutta e al cibo. La stessa parola, utilizzata in un testo che tratta tecnologia, dovrebbe essere avvicinata allo spazio di vettori che rappresenta iphone, smartphone, aziende hi-tech, ecc ecc. Il meccanismo dell'attention manipola la parola asettica (o, per dire meglio, i suoi embeddings) al fine di dargli la semantica giusta in base al contesto in cui si trova.
E funziona incredibilmente bene! Come in una pozione magica, aggiungendo all'ingrediente base (gli embeddings) un pò della parola prima, un pò della parola dopo, arricchiamo la parola iniziale di ulteriore significato! Non a caso ovviamente, ma l'attention serve proprio a dare un peso alle parole che hanno più significato per il token che si sta considerando e a relazionarle solo nella misura necessaria.
L'architettura Transformer, sebbene molto più complessa di come qui introdotta e sebbene includa altri blocchi che meriterebbe una trattazione a parte (positional encoding, encoder, decoder, FFN), ha una caratteristica importantissima: è costruita su operazioni matriciali che si prestano molto bene al calcolo parallelo (per questo le GPU sono utilissime). Questa caratteristica ha permesso di abbattere i tempi di training e progettare modelli con moltissimi parametri, trainabili con un gran numero di dati e testi in input.
È utile distinguere due momenti diversi:
- Addestramento (training): è la fase in cui il modello impara dai dati. Richiede enormi quantità di calcolo, tempo ed energia.
- Utilizzo (inference): è quando noi facciamo una domanda e riceviamo una risposta. Molto meno costoso, ma non gratuito.
Questo spiega perché poche aziende al mondo addestrano modelli giganteschi, mentre moltissime altre si limitano a usarli o adattarli a casi specifici.
Date queste premesse, non senza un salto quantico spaventoso, arriviamo ai ben noti modelli moderni che tutti conosciamo: GPT, Claude, Grok, Deepseek, Gemini, llama e chi più ne ha più ne metta - modelli capaci di sfornare risposte straordinariamente precise a domande complesse, dove la scelta della risposta (aka token) più probabile si mischia e si (con)fonde con capacità di ragionamento che assomigliano quasi pericolosamente a quelle umane (sebbene sia chiaro a tutti che non sia una reale capacità intellettiva ma solo, appunto, un calcolo probabilistico basato essenzialmente sui dati di addestramento).
Hallucinations – quando l’AI si inventa le risposte
Assomigliano dicevamo... Ma tra l'apparenza e la sostanza a volte ci passa un filo sottile. A questo proposito, un aspetto poco intuitivo dei modelli di linguaggio è il fenomeno delle hallucinations: risposte che sembrano corrette, ben scritte e convincenti… ma che in realtà sono sbagliate o completamente inventate.
Questo succede perché un LLM non cerca la verità, ma la risposta più probabile data una domanda. Se non “sa” qualcosa, tende comunque a rispondere, riempiendo i vuoti in modo plausibile.
È per questo che l’AI può citare libri che non esistono, inventare riferimenti legali o spiegare con sicurezza concetti errati.
Non è malafede: è il modo in cui funziona. Ed è anche il motivo per cui l’AI non può (ancora) essere lasciata senza supervisione umana, soprattutto in contesti critici.
Vibe che?
Uno degli ambiti che sta vivendo un momentum è proprio quello relativo al coding: infatti la capacità di questi modelli di tirare fuori soluzioni accurate e ingegnerizzate (a volte forse troppo...) ha impressionato colonie di sviluppatori.
Approcci come il vibe coding si stanno facendo strada, specialmente tra coloro che approcciano l'AI per la prima volta. A questo proposito, esistono diverse definizioni per questa tecnica di uso dell'AI e non è questa la sede per esplorarle tutte. Sintetizzando, si tratta di creare dei prompt per un agente affinché questi li traduca in codice che implementa le specifiche, fornite in maniera informale, con linguaggio naturale. L'approccio è tipicamente conversazionale e può prevedere una serie di iterazioni attraverso cui l'utente umano rifinisce la soluzione prodotta guidando l'agente, aggiungendo specifiche, suggerendo soluzioni sempre più precise, ecc.
Il vibe coding si rivela uno strumento estremamente potente, specialmente nella produzione rapida di prototipi funzionanti. Potremmo quasi dire che rilascia delle scariche di adrenalina non irrilevanti in chi lo usa per l'immediatezza dei risultati che si riescono a ottenere e, spesso, anche per la buona precisione dell'output.
Vibe coding? No grazie!
Il vibe coding non è però l'unico approccio possibile all'uso dell'AI per task di coding. Anzi, in certi ambiti, come diremo a breve, non è nemmeno il più consigliato! Alcuni developer stanno infatti propendendo sempre di più per un approccio più strutturato, ovvero l'inserimento dell'AI in maniera più organica nel workflow di sviluppo. Secondo questo approccio, l'agente viene prima guidato attraverso delle regole generiche che vengono date a priori dove essenzialmente:
- si descrive il progetto e le finalità che si prefigge di raggiungere;
- si descrivono le code convention da adottare (magari il team ha già delle regole ben precise che adotta quotidianamente);
- si descrivono i pattern e le best practise, oltre che le librerie da adottare e le modalità di sviluppo consentite;
- si descrive le tipologie di task più comuni per il progetto e il modo corretto di affrontarle (di nuovo, il team potrebbe già avere dei pattern ricorrenti in pancia che usa in determinate situazioni);
A fronte di queste regole, vengono fornite delle specifiche di alto livello all'agente con la richiesta di generare le specifiche tecniche e un piano operativo per l'implementazione. L'output di questa fase non è quindi più codice ma un piano/documentazione tecnica per un successivo step.
La review umana si concentra quindi sulle specifiche prodotte. Al termine di questa fase di controllo viene nuovamente triggerato un agente con lo scopo di tradurre le specifiche in codice, sempre tenendo presenti le regole generali summenzionate. Semplificando, facciamo assumere all'agente prima il ruolo di Senior Analyst/Solution Architect e poi quello di Senior developer.
Il maggiore contesto fornito all'AI in tutte le fasi e il concentrarsi su un task alla volta - prima progettazione e, dopo, coding vero e proprio - fornisce dei risultati molto più precisi e di qualità, paragonabili, secondo alcuni, all'operato di un analista senior e di un senior developer combinati insieme in una catena.
Vibe vs Structured
Si delineano quindi gli scenari in cui le due tecniche possono teoricamente dare i risultati migliori:
VIBE CODING
Creazione rapida di prototipi, validazione di idee, esplorazione di librerie e tecnologie, implementazione di algoritmi ben codificati e che hanno ampia letteratura, implementazione di task ripetitivi.
APPROCCIO STRUTTURATO
Integrazione in flussi di lavoro più articolati, implementazione di pezzi di codice production-ready, rispetto di regole ben precise per integrazione con progetti pre-esistenti, applicazione di pattern non standard o non ampiamente documentati in letteratura, soluzioni custom team-based.
Favorisca l'IDE!
Esistono sul mercato svariati tool (tendenzialmente a pagamento) che integrano un IDE a tutto tondo con una serie di funzionalità votate all'AI. E possono lavorare sia in modalità vibe coding che approccio strutturato:
- Cursor è sicuramente uno dei più famosi. Si basa su vscode e aggiunge potenti funzionalità per fornire contesto al prompt in maniera precisa, possibilità di aggiungere regole generali che l'AI dovrà rispettare nel fornire le risposte e anche delle chat mode specifiche per task ricorrenti (bugfix, enhancement, ecc...). Il costo è relativamente basso ed è ad oggi uno dei player da considerare;
https://cursor.com/pricing - MS Copilot, è più un'estensione per vscode piuttosto che un brand new editor e fornisce anche lui funzionalità molto più avanzate della singola "ennesima" chat con l'n-esimo agente AI;
https://code.visualstudio.com/docs/copilot/overview - Kiro, l'IDE di Amazon dedicato all'AI, era in beta fino a poco tempo fa ma già promette funzionalità cutting-edge per chi è interessato a vibe coding e dintorni.
https://kiro.dev/
Sicuramente ce ne sono altri rilevanti in questo ambito oppure ne verranno fuori in futuro. Aggiungeteli nei commenti con le vostre considerazioni, se vi va, indicando eventuali punti di forza/debolezza se li avete già provati in un vostro progetto.
Personalmente sto testando a fondo le capacità di Cursor e confermo che se la cava bene sia con vibe coding puro, sia utilizzando delle regole più rigide (vedi cursorrules + chat modes per ulteriori approfondimenti).
Non è tutto code quello che compila
Tra i rischi concreti per team di tutte le dimensioni è, a mio parere, impossibile non citare quello di accumulare un forte debito tecnico applicando la tecnica sbagliata in base al tipo di progetto, ad esempio vibe coding a progetti complessi che devono essere production ready e bullet proof. Oppure approcci troppo strutturati a progetti semplici che tendono a over-ingegnerizzare il codice e, quindi, lo complicano inutilmente.
Sempre sul vibe coding, proprio perchè viene dato molto meno contesto all'AI, è più aleatorio il livello di qualità dell'output. Può andare molto bene, può andare molto male (e quindi l'output dovrà essere cestinato). Non si sa. Tutto è possibile.
In generale per evitare questi rischi è necessaria una buona seniority dell'utente umano o del cosiddetto prompt engineer (se qualcuno ha capito esattamente cosa sia...), utile per:
- individuare la tecnica giusta da applicare;
- redigere le regole opportune con gli hints corretti per l'AI;
- revisionare l'output dell'AI (specifiche tecniche/piano di lavoro oppure codice);
- valutare se la qualità prodotta è in linea con ciò che il team/progetto/cliente si aspettano;
- valutare potenziali falle di sicurezza non correttamente gestite dall'AI.
Tutte queste attività non sono banali, non vanno sottovalutate e non sempre possono essere demandate esclusivamente a dei junior developers. Per esempio è difficile valutare la qualità di una soluzione che non si sarebbe stati in grado di produrre autonomamente o se non se ne conoscono i pattern applicati, i limiti tecnici o le condizioni in cui questa performa al meglio.
Per non parlare dei tanti altri rischi connessi all'adozione incontrollata di strumenti AI: scarso controllo dei costi che possono crescere in maniera significativa man mano che si adottano sempre più tool, potenziale lock-in su determinate aree specifiche come code review, design to code e altre aree affini, sicurezza e privacy dei dati, manutenzione dei modelli, ecc ecc. E questi sono solo alcuni dei temi che le organizzazioni stanno affrontando.
AI in azienda: da dove partire senza farsi male
Prima di “buttarsi” sull’intelligenza artificiale, soprattutto in azienda, conviene fermarsi un attimo e farsi alcune domande molto concrete:
- Per cosa vogliamo usarla davvero?
Riassumere documenti? Supportare il customer care? Scrivere codice? Non tutto va automatizzato, e non tutto va fatto con un LLM. - Che dati stiamo usando?
Dati sensibili, personali o riservati non dovrebbero mai finire “per sbaglio” in sistemi esterni senza una policy chiara. - Chi controlla l’output?
L’AI può aiutare, ma l’ultima parola deve restare a una persona. Sempre. - Quanto ci costa?
I modelli non sono magici né gratuiti: tra infrastruttura, API e manutenzione, i costi vanno monitorati come qualsiasi altro servizio.
In breve: l’AI funziona meglio quando è uno strumento ben governato, non quando è lasciata libera di “fare tutto”.
Punto di vista da Dev
Per come la vedo io, l'AI usata in ambiti come il coding o la produzione di documentazione, è come un amplificatore applicato alle nostre mani, alle nostre menti. Se la mente contiene confusione, l'AI molto probabilmente amplificherà questa confusione. Se siamo invece in grado di guidare con precisione la soluzione avendo già in mente dove andare a parare (e quindi usando l'AI solo per arrivarci prima) allora può davvero rappresentare una straordinaria opportunità di amplificare le nostre capacità e, quindi, produrre valore in ambiti sconfinati, non solo nella produzione di software.
Wrap-up
Personalmente credo che il modello di governance dell'AI nelle aziende sia ancora un processo poco studiato e che richiederà figure aziendali specializzate che se ne occupino a tempo pieno. Il rischio, da un lato, è quello di perdere un'opportunità concreta per: (i) efficientare processi aziendali, (ii) potenziare i team con dei tool indubbiamente efficaci, se usati nel modo corretto, (iii) fare di più con meno. Dall'altro lato, i rischi legati al debito tecnico o gli altri aspetti che ho menzionato, possono deludere le aspettative che un pò tutti gli addetti ai lavori stanno riponendo in questa importante rivoluzione tecnologica. Guidare questa trasformazione nel modo corretto farà la differenza tra le aziende che la cavalcheranno con successo e quelle che rimarranno ferme al palo, perdendo sempre più terreno nei confronti dei competitor.